
Amazon AthenaのUNLOADステートメント使用時のパーティション周りの動作を確認してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
今回は、Amazon AthenaのUNLOADステートメントについて調べる機会があり、その際にパーティション周りの動作が気になったので確認してみました。
UNLOADステートメントとは
UNLOADステートメントを使うと、SELECTクエリの結果を指定のフォーマットで書き込むことができます。
構文は次のようになります。
UNLOAD (SELECT col_name[, ...] FROM old_table) TO 's3://my_athena_data_location/my_folder/' WITH ( property_name = 'expression' [, ...] )
ここで、データ入力元はSELECTクエリなのでGlue Tableを指定して使えますが、データ出力先となるTOではGlue Tableではなくバケット名を直接指定しているため、パーティションスキーマの扱いがどうなるのか気になりました。この辺りを動作確認で検証してみます。
やってみた
環境準備
必要なリソースをAWS CDKで作成します。
import {
aws_athena,
aws_glue,
aws_s3,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as aws_glue_alpha from '@aws-cdk/aws-glue-alpha';
export class AwsCdkAppStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props);
new aws_athena.CfnWorkGroup(this, 'workGroupV3', {
name: 'workGroupVersionSpecified',
workGroupConfiguration: {
engineVersion: {
selectedEngineVersion: 'Athena engine version 3',
},
},
});
//入力元S3 Bucket
const sourceBucket = new aws_s3.Bucket(this, 'sourcebucket', {
bucketName: '20221017-sourcebucket',
removalPolicy: RemovalPolicy.DESTROY,
});
//出力先S3 Bucket
const targetBucket = new aws_s3.Bucket(this, 'targetbucket', {
bucketName: '20221017-targetbucket',
removalPolicy: RemovalPolicy.DESTROY,
});
const glueDatabase = new aws_glue_alpha.Database(this, 'glueDatabase', {
databaseName: 'gluedatabase',
});
//入力元Glue Table
const sourceGlueTable = new aws_glue_alpha.Table(this, 'sourceGlueTable', {
tableName: 'source_glue_table',
database: glueDatabase,
bucket: sourceBucket,
s3Prefix: 'data/',
partitionKeys: [
{
name: 'date',
type: aws_glue_alpha.Schema.STRING,
},
],
dataFormat: aws_glue_alpha.DataFormat.JSON,
columns: [
{
name: 'deviceId',
type: aws_glue_alpha.Schema.STRING,
},
{
name: 'maxTemperature',
type: aws_glue_alpha.Schema.FLOAT,
},
],
});
//入力元Glue TableのPartition Proojection設定
const cfnSourceGlueTable = sourceGlueTable.node
.defaultChild as aws_glue.CfnTable;
cfnSourceGlueTable.addPropertyOverride('TableInput.Parameters', {
'projection.enabled': true,
'projection.date.type': 'date',
'projection.date.range': '2022/10/01,NOW',
'projection.date.format': 'yyyy/MM/dd',
'projection.date.interval': 1,
'projection.date.interval.unit': 'DAYS',
'storage.location.template':
`s3://${sourceBucket.bucketName}/data/` + '${date}',
});
//出力先Glue Table
const targetGlueTable = new aws_glue_alpha.Table(this, 'targetGlueTable', {
tableName: 'target_glue_table',
database: glueDatabase,
bucket: targetBucket,
s3Prefix: 'data/',
partitionKeys: [
{
name: 'date',
type: aws_glue_alpha.Schema.STRING,
},
],
dataFormat: aws_glue_alpha.DataFormat.PARQUET,
columns: [
{
name: 'deviceId',
type: aws_glue_alpha.Schema.STRING,
},
{
name: 'maxTemperature',
type: aws_glue_alpha.Schema.FLOAT,
},
],
});
//出力先Glue TableのPartition Projection設定
const cfnTargetGlueTable = targetGlueTable.node
.defaultChild as aws_glue.CfnTable;
cfnTargetGlueTable.addPropertyOverride('TableInput.Parameters', {
'projection.enabled': true,
'projection.date.type': 'date',
'projection.date.range': '2022/10/01,NOW',
'projection.date.format': 'yyyy/MM/dd',
'projection.date.interval': 1,
'projection.date.interval.unit': 'DAYS',
'storage.location.template':
`s3://${targetBucket.bucketName}/data/` + '${date}',
});
}
}
- UNLOADのデータ入力元および出力先に、AthenaのPartition Projectionで非Hiveな形式のパーティション(
yyyy/MM/dd)を設定しています。 - 予想通りではあったのですが、出力先のGlue TableやPartition Projection設定は使用されない動作となりました。
入力元のバケットにデータをアップロードします。
$ cat data1.json
{"deviceId":"d001","maxTemperature":19.1}
{"deviceId":"d002","maxTemperature":22.9}
{"deviceId":"d003","maxTemperature":23.3}
$ cat data2.json
{"deviceId":"d001","maxTemperature":22.7}
{"deviceId":"d002","maxTemperature":20.5}
{"deviceId":"d003","maxTemperature":18.6}
$ cat data3.json
{"deviceId":"d001","maxTemperature":19.8}
{"deviceId":"d002","maxTemperature":21.0}
{"deviceId":"d003","maxTemperature":21.2}
aws s3 cp data1.json s3://${BUCKET_NAME}/data/2022/10/15/data1.json
aws s3 cp data2.json s3://${BUCKET_NAME}/data/2022/10/16/data2.json
aws s3 cp data3.json s3://${BUCKET_NAME}/data/2022/10/17/data3.json
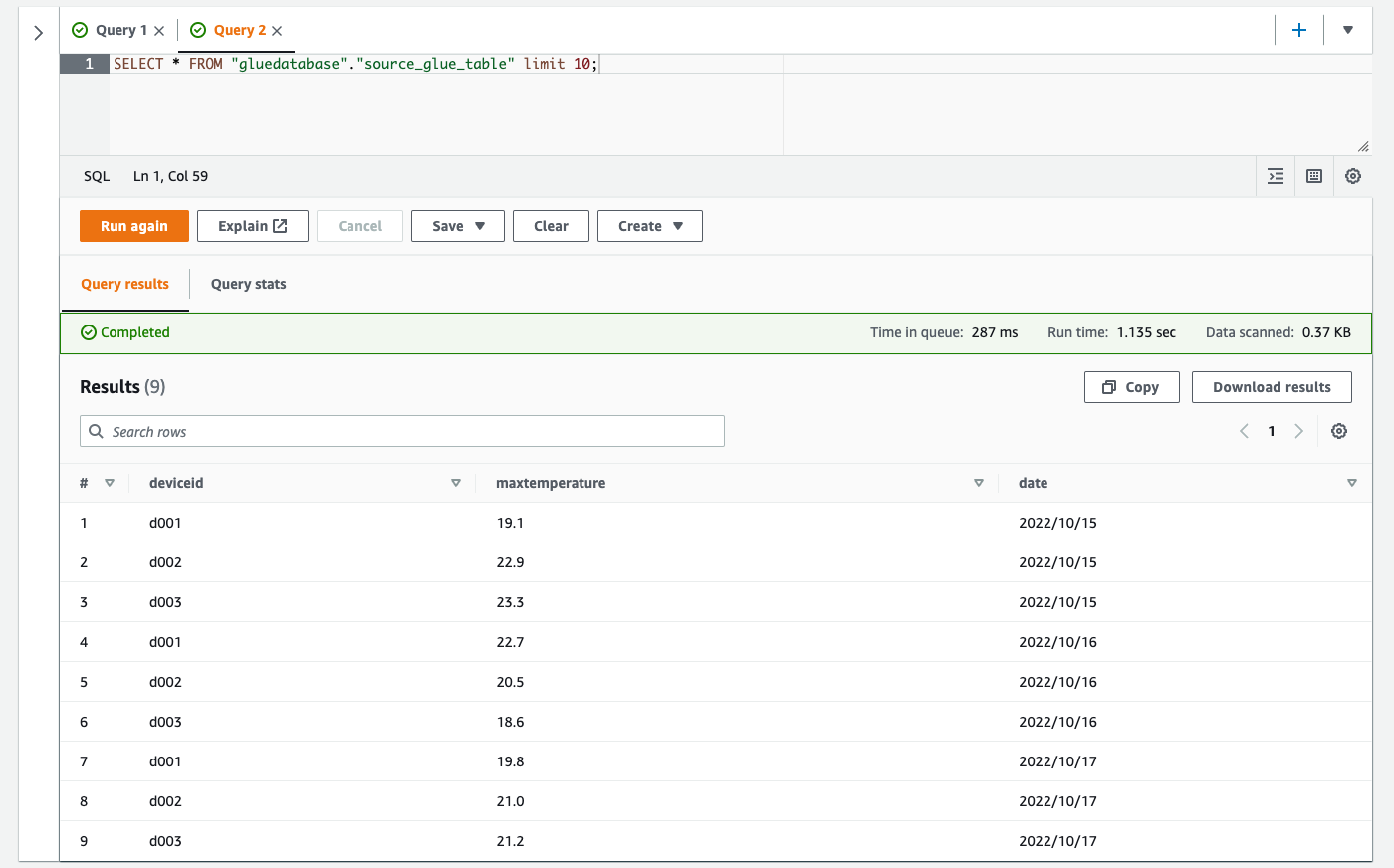
SELECTクエリを打つと問題なくデータが取得できています。
SELECT * FROM "gluedatabase"."source_glue_table" limit 10;
動作確認
UNLOADステートメントではWITHでオプションとしてpartitioned_byを指定できます。指定する場合としない場合とでどのような動作になるか確認してみます。
その1(partitioned_byを指定しない場合)
まずpartitioned_byを指定しないでUNLOADステートメントを実行してみます。
UNLOAD (SELECT * FROM source_glue_table) TO 's3://20221017-targetbucket/data/' WITH (format = 'JSON')
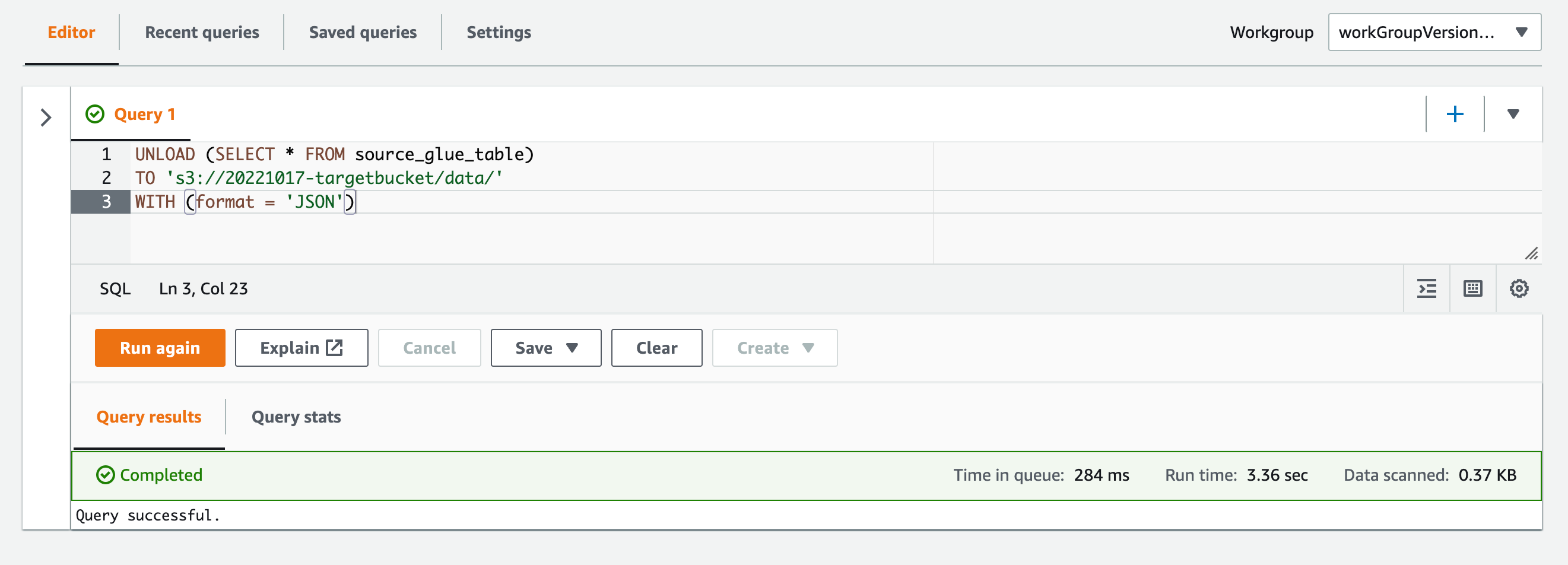
バケット内を確認すると、パーティションでパスが分けられず、1つのオブジェクトが作成されています。
$ aws s3 ls s3://20221017-targetbucket/data/ 2022-10-17 20:51:40 140 20221017_115137_00007_43sda_df6e7895-ce6f-4af4-a552-746c7b18499c.gz
オブジェクト内容を見ると、入力元データではパーティションスキーマであったdateが通常のスキーマとなっています。
{"deviceid": "d001", "maxtemperature": 19.1, "date": "2022/10/15"}
{"deviceid": "d002","maxtemperature": 22.9, "date": "2022/10/15"}
{"deviceid": "d003","maxtemperature": 23.3, "date": "2022/10/15"}
{"deviceid": "d001","maxtemperature": 19.8, "date": "2022/10/17"}
{"deviceid": "d002","maxtemperature": 21, "date": "2022/10/17"}
{"deviceid": "d003","maxtemperature": 21.2, "date": "2022/10/17"}
{"deviceid": "d001","maxtemperature": 22.7, "date": "2022/10/16"}
{"deviceid": "d002","maxtemperature": 20.5, "date": "2022/10/16"}
{"deviceid": "d003","maxtemperature": 18.6, "date": "2022/10/16"}
出力先でパーティションスキーマを使用しない場合はpartitioned_byの指定なしで良さそうです。
その2(partitioned_byを指定した場合)
次にpartitioned_byを指定してUNLOADステートメントを実行してみます。
UNLOAD (SELECT * FROM source_glue_table) TO 's3://20221017-targetbucket/data/' WITH (format = 'JSON', partitioned_by = ARRAY['date'])
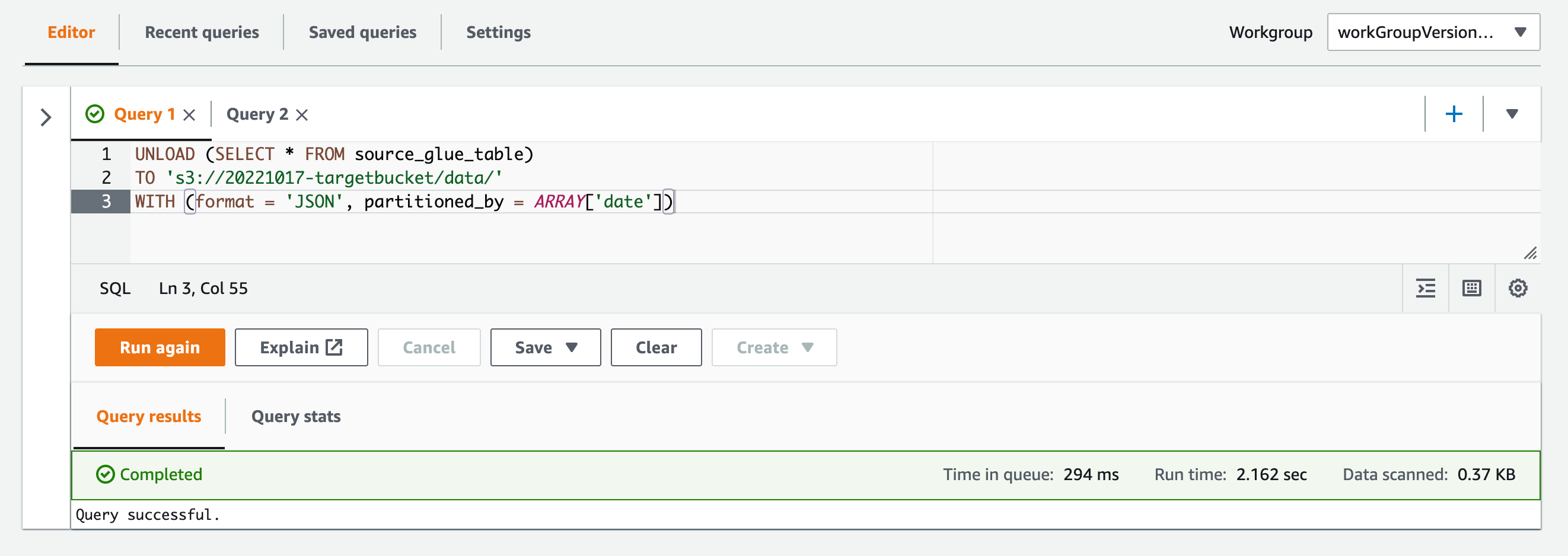
バケット内を確認すると、Hive形式でパーティションパスが作られていました。
$ aws s3 ls s3://20221017-targetbucket/data/
PRE date=2022%2F10%2F15/
PRE date=2022%2F10%2F16/
PRE date=2022%2F10%2F17/
オブジェクト内容を見ると、パーティション以外のスキーマが保持されています。
{"deviceid": "d001", "maxtemperature": 19.1}
{"deviceid": "d002", "maxtemperature": 22.9}
{"deviceid": "d003", "maxtemperature": 23.3}
UNLOADの構文ではパーティションの形式をHiveや非Hiveで指定する方法は無いようです。よって出力データでHive形式なパーティションを使用する場合に限りpartitioned_byを指定することになりそうです。
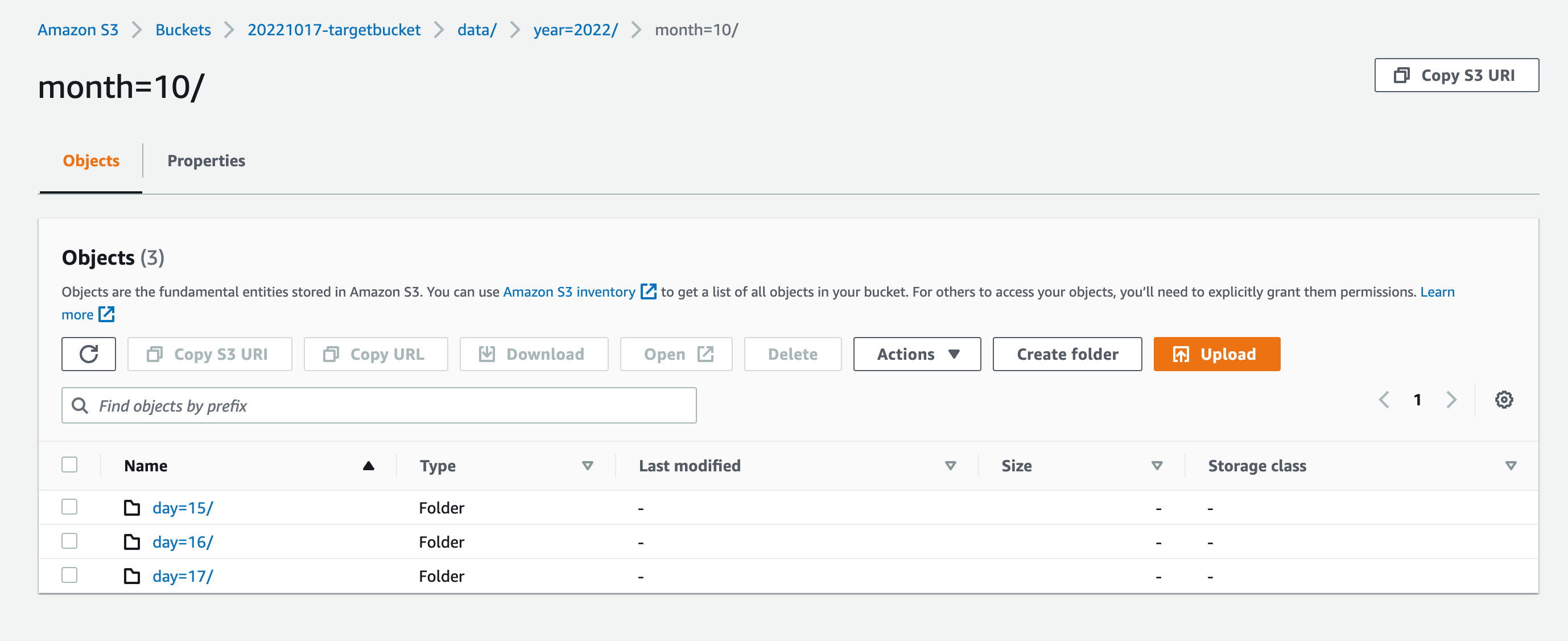
データがHive形式であること前提であれば、次のようにパーティションパスを問題なく作ることができました。
UNLOAD ( SELECT deviceid, maxtemperature, split_part(date, '/', 1) as year, split_part(date, '/', 2) as month, split_part(date, '/', 3) as day FROM source_glue_table ) TO 's3://20221017-targetbucket/data/' WITH (format = 'JSON', partitioned_by = ARRAY [ 'year', 'month', 'day' ])
まとめ
- 入力元データはGlue Table経由で取得できるが、出力先はGlue Tableを経由せずにS3 Bucketを直接指定する。よってパーティションスキーマを
partitioned_byで明示的に指定する必要がある。 partitioned_by指定時の出力データのパーティションパスは必ずHive形式となる。
補足:出力先パス(TO)の配下にオブジェクトが既に存在しているとエラーとなる
出力先パス(TO)の配下にオブジェクトが既に存在しているとUNLOADによる書き込みはできないようです。
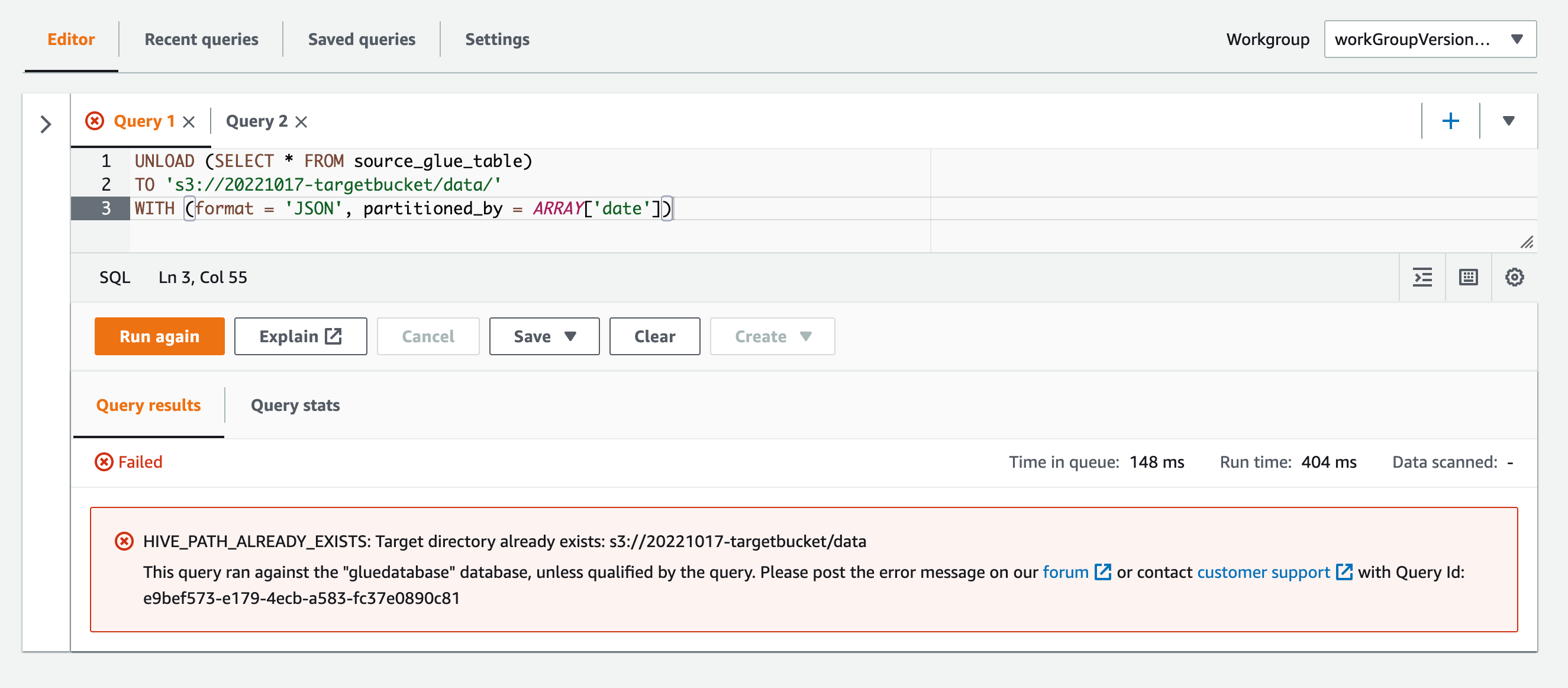
HIVE_PATH_ALREADY_EXISTS: Target directory already exists: s3://20221017-targetbucket/data This query ran against the "gluedatabase" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: e9bef573-e179-4ecb-a583-fc37e0890c81
このことはドキュメントにも記載があります。
The TO destination must specify a location in Amazon S3 that has no data. Before the UNLOAD query writes to the location specified, it verifies that the bucket location is empty. Because UNLOAD does not write data to the specified location if the location already has data in it, UNLOAD does not overwrite existing data. To reuse a bucket location as a destination for UNLOAD, delete the data in the bucket location, and then run the query again.
よって、UNLOAD実行前に出力先パス配下のオブジェクトがすべて削除されている必要があり、運用としてそれで問題ないかは要確認となりそうです。
参考
以上









